
浪潮信息AIStation实战:精密制造企业多Agent并行运转的底座选择
早上九点,硬件研发工程师小王在企业智能工作台输入了一条需求:"需要一款5V转3.3V、额定电流1A、封装SOT-23的LDO稳压芯片,工作温度范围须覆盖-40℃至85℃。"不到三秒,系统便推送了三款符合条件的备选物料,并依据库存水位自动排序:首选料库存15K,次选料库存8K,第三款仅余0.2K且交期长达20周,系统已将其自动置灰提示。小王一键选定库存最充裕的物料导入BOM表,系统同步生成备注:"现货充足,可直接替换,无需重新打样。"
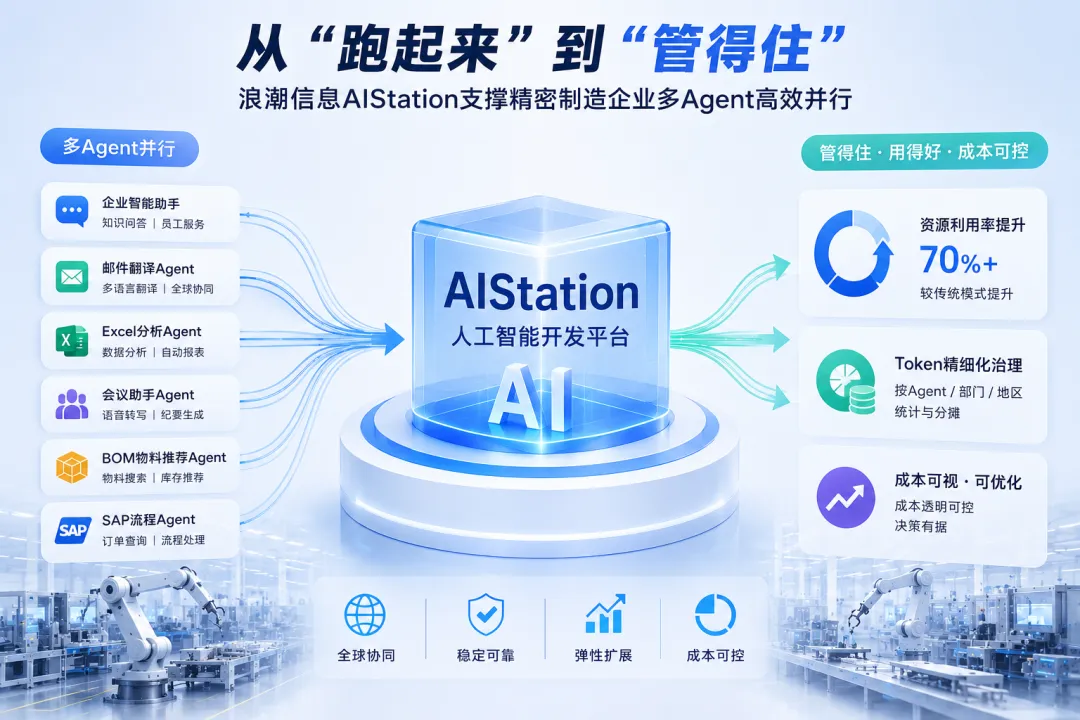
这一幕,只是这家坐拥数十万名员工的全球化精密制造企业中,智能化应用加速落地的一个缩影。目前,该企业已自主研发并上线超过20款Agent应用,且以平均每两周迭代一款的节奏持续推进,覆盖范围从企业智能助手、邮件多语种翻译、Excel数据智能分析、会议全程辅助等日常办公场景,延伸至工业图纸理解、产品外观质检等核心生产环节。
随着企业从单一Agent试点迈向多Agent并行部署,挑战也随之升级:不同Agent在调用频率、并发峰值、模型需求上差异显著,容易引发资源争抢、任务排队导致响应变慢;同时,多Agent部署下token消耗量呈指数级增长,使企业面临“Agent越多,成本越难控”的问题。
针对以上挑战,浪潮信息人工智能开发平台AIStation为精密制造企业的多智能体应用打造了高稳定、高可用的推理运行环境:一方面,平台根据不同推理任务负载动态分配算力资源,让企业在相同硬件条件下运行更多Agent实例;另一方面,通过对token消耗、调用量进行精细化管理,让智能体应用成本可预测、可优化,为扩缩容提供科学依据。
01 多Agent并行落地,精密制造企业智能化转型步入深水区
作为精密制造领域的先进企业,该公司在全球拥有多个生产基地和研发中心,公司目前正规划基于AI Agent能力来提升内部办公、生产作业的工作效率,实现降本增效。随着Agent部署数量增加,企业很快意识到,真正的挑战不在于“能否做出Agent”,而在于“如何让多个Agent稳定运行、持续迭代,并真正赋能业务”。
■ 系统须具备大规模并发与峰值流量管理能力
在如此大规模的全球化企业中,AI Agent的访问高峰呈现出多区域叠加、多场景共振的特征:上班前后企业助手集中咨询、邮件高峰期翻译请求暴增、会议结束后纪要生成扎堆、月末季度末数据分析需求激增,以及管理层集中调用报告类Agent——这些峰值往往短时间内同时涌向算力系统。
在缺乏大规模流量管理的情况下,多智能体系统将频繁陷入响应变慢、请求排队、任务超时的窘境——随着智能体数量增加和调用频率上升,大量请求同时涌入,算力资源被迅速占满,超出处理能力的请求被迫进入等待队列,部分请求因等待时间超过预设阈值而被丢弃,导致业务中断或重复提交。
■ 规模化Agent应用带来的成本失控与决策失据
当Agent从试点走向规模化部署,成本失控风险显著上升。除了GPU硬件,推理检索、语音转写、文档解析及多轮工具调用等环节持续叠加成本,而因Agent出错导致的重复调用进一步加剧浪费。同时,多智能体并发增加时,传统弹性伸缩策略难以适配大模型特性:GPU利用率在请求为0时趋近0%,一旦有请求便飙升至95%以上且长期维持高位,缺乏区分度,导致运维无法判断扩缩容时机。
这种负载度量盲区也使IT部门在算力采购时缺乏客观依据,难以回答实际需求与峰值缺口等关键问题。更严重的是,企业算力平台普遍缺乏精细化成本分析能力,无法识别哪些Agent调用最频繁、哪些部门token消耗最高、哪些请求因失败被反复执行、哪些任务适合批处理或缓存。
02 AIStation构建多Agent统一运行与治理底座
针对以上问题,AIStation为企业构建了面向多Agent应用的统一支撑平台,通过精细化的算力调度与token管理,将资源利用率从传统静态分配模式下的不足30%提升至70%以上。在此基础上,AIStation依据token消耗、任务时长、应用优先级等多维指标,实现资源度量与成本精细化控制,为系统扩缩容提供科学依据。
// 从“静态分配”走向“弹性混部”,承载企业级并发洪峰
面对并发洪峰,AIStation基于统一模型服务管理与资源池化架构,将GPU、CPU、内存、存储、网络及推理实例统一纳管,避免不同Agent重复建设、独占资源。平台可根据业务优先级、时延要求和SLA目标,启动并发限流、优先级队列以及弹性扩缩容等机制,对流量高峰进行实时调度与缓冲。
对于企业智能助手、SAP/OA流程Agent等在线实时业务,平台优先保障响应体验;对于邮件批量翻译、会议纪要生成、Excel订单汇总等非实时任务,则可自动转入低峰时段执行,复用闲置资源。通过“在线优先、离线混部、低峰复用、动态弹性”的机制,AIStation将客户整体算力利用率由不足30%提升至70%以上,显著降低冗余资源建设和额外GPU采购需求。
// 从“资源监控”走向“token级经营”,破解规模化Agent成本黑箱
针对规模化Agent应用带来的成本失控与决策失据问题,AIStation通过大模型服务网关,对不同Agent、模型和工具调用建立统一入口管理,将原本分散在检索、语音、文档解析和多轮工具调用中的成本,纳入统一可观测体系。
平台不再只依赖QPS和GPU利用率判断负载,而是引入token消耗、token配额、单次AI任务成本等指标,可按Agent、部门、地区和任务类型进行统计,实现精准的按量计费与成本分摊。
在此基础上,AIStation支持为不同Agent设置差异化配额与限流策略。对于企业助手等高频基础应用,平台保障稳定响应;对于长文档翻译、批量报告生成、订单数据汇总等高消耗任务,则可设置token上限、并发阈值和任务排队机制,避免单一部门或单一任务持续占用推理资源。
通过引入AIStation,该企业将20余个自研Agent从单点试用推进到统一平台化运行,逐步形成覆盖开发、部署、推理、调度与治理的一体化能力。在办公协同场景中,企业智能助手、邮件翻译、文档生成和会议助手提升了全球员工协作效率;在业务流程场景中,SAP、OA相关Agent逐步进入订单查询、流程处理、财务与供应链协同等高频环节,推动部分业务请求由人工处理向智能响应转变。
对于迈向全球化布局的精密制造企业来说,浪潮信息AIStation所带来的价值,远不止于让更多Agent顺利上线运行,更在于帮助企业从底层夯实一套具备稳定运行、弹性伸缩、成本精治、持续演进能力的企业级Agent基础设施体系——让AI Agent真正完成从实验室概念验证到生产环境可靠落地的关键跨越,成为驱动业务增长的实际生产力。
相关阅读
- 人才换血、资金加码,ST中润密集发公告加速破局重生
- 2026年山东盛世达管道排水管定制相关内容梳理
- 乡村好医生李波:传承与创新的医学之路
- 电商破圈发力!廣氏多款健康新品上新,线上矩阵引爆增长新引擎
- 全链条筑牢食安防线,金锣以严苛标准守护舌尖安全
- 开合间 见非凡 HUAWEI Mate XTs丨ULTIMATE DESIGN尊享品鉴会 圆满落幕
- 完美收官!第四届青岛地铁APP云上城市穿梭赛参与者超过10万,共倡绿色出行、健康生活理念
- 中数智汇ESG中小企业数据库 助力银行赋能可持续发展
- 金锣:感知消费风向 推动健康肉制品多元化创新
- 暖心助考 为梦护航|中建东孚华北分公司京济两地同步开展高考护考志愿服务